
How DataBase Engine Returns Row from Disk!
Very high level understanding of how database returns rows to the user of the database, which the applications.
This is a very high-level database understanding for mine. In the last weeks, I have read some database internal designs, how they work etc, etc. While reading those I found some interesting thoughts.
So in this post, I will try to explain how a generic SQL database returns data to the users from the inside.
💡 This is a very generic high-level idea.
Small Story 1:
A file:
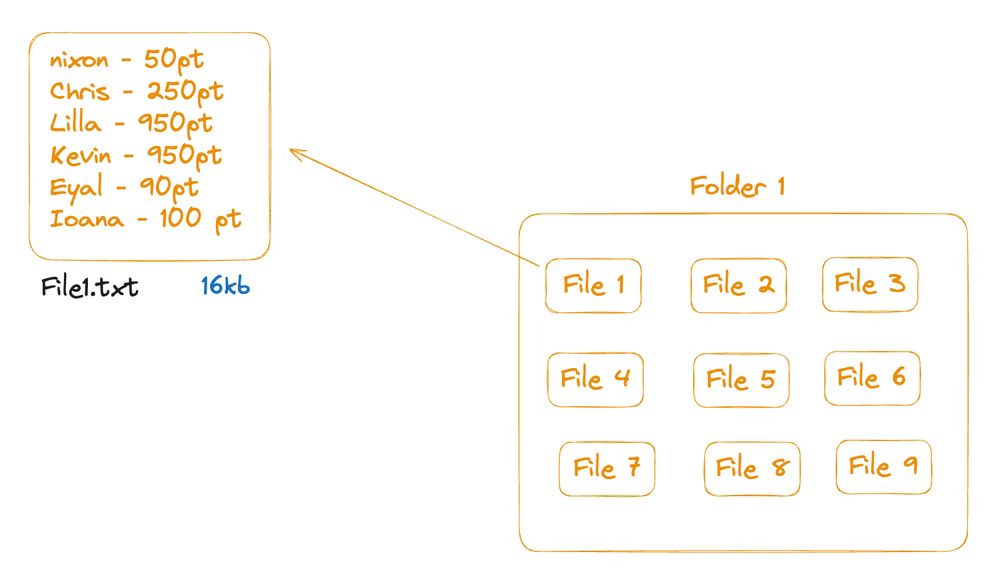
let's imagine a file! We can write anything in the file here. The only constraint it will have is its size. The size of the file can not be more than 16kb.

A folder of files:
Now I wanna store a lot of info in a similar file. What will I do? I will create a folder to save all of the files in there.
So How do I find a row(Kevin) from the folder?
Imagine the old days, when you have to open files one by one to see if that's the file or not 😅.
💡 Now this is how a database generally stores data in the disk.
Returning Data without Index:
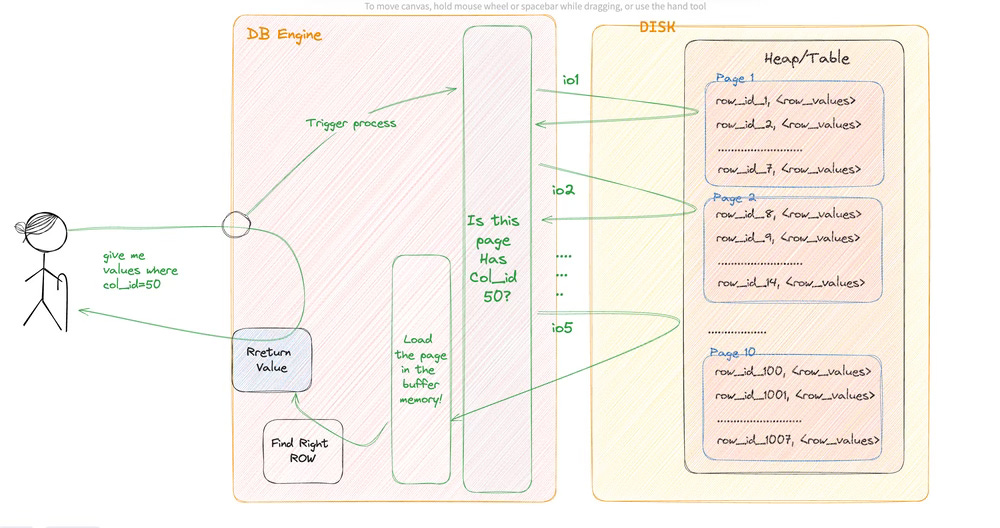
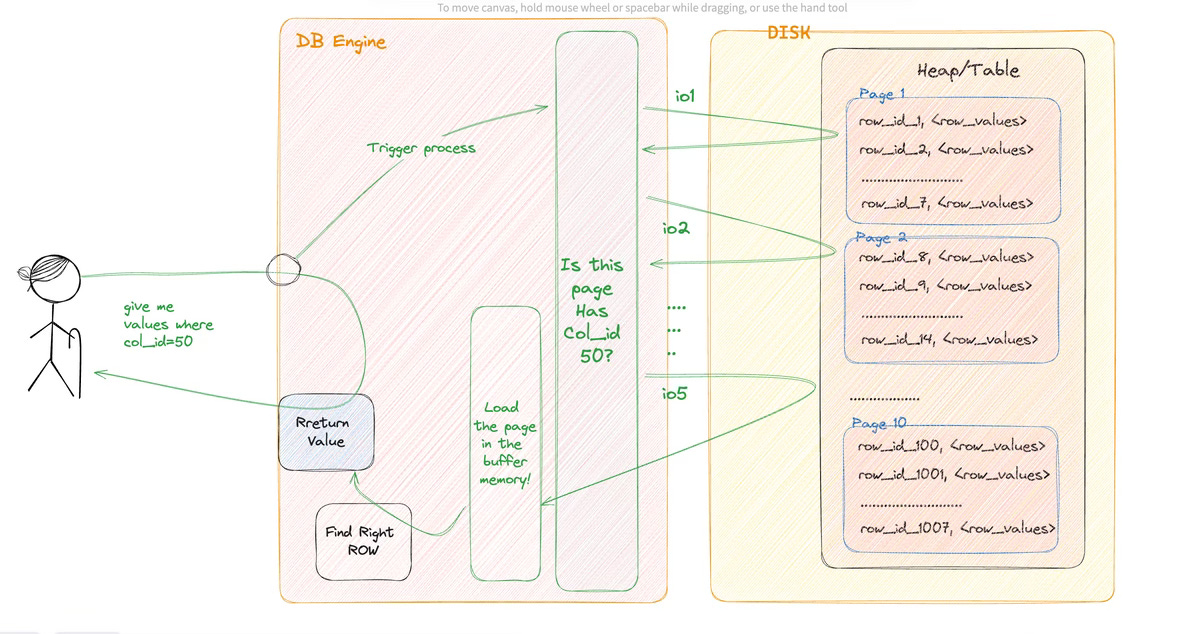
Now if you look at the image `003`. Before jumping into the process, let me point out some names here,
pages (previously we called them files), where we store data from our table. We can assume our row-based data will be stored as a row in the file with a row ID generated from the database. That row ID is internal to the database itself
Heap/table where it represents the table itself, previously we called them folders. and it stores the pages.
💡 I am gonna ignore a lot of details here, just to make it a bit simplistic.
Now, looking into the process I think the process is kind of like the following:
We asked DB engine, "give me all values for a row where column = 50"
DB engine will start a process
the process will look for the heap/table for the pages
now to look for the right values the DB loads the first page and sees there is no column in the page
the way the db engine called the page it's called io
and the process goes on till it finds the right page
...........
once it finds the right page, the db engine will load the page into its buffer memory.
Then it will extract the row value which has the right column value
After that, the row will be returned to the user.
Food for thought:
if a table has 1 million rows, then how many pages it will have?
if each row has 50 columns, how will that impact the page-storing behaviors?
if 1 or more columns have JSON type datatype, how will it impact the pages?
what will be the IO for finding one row in these scenarios?
what will happen if we run a join query between two tables?
Small Story 2:
A special File:
Let me create another file called specialFile1.txt. There I will only store the primary info of the file, and its location. The file size is still the same 16kb!

A special Folder for Special Files:
Yes! You guessed it right! We will use a different type of folders to store those special files.
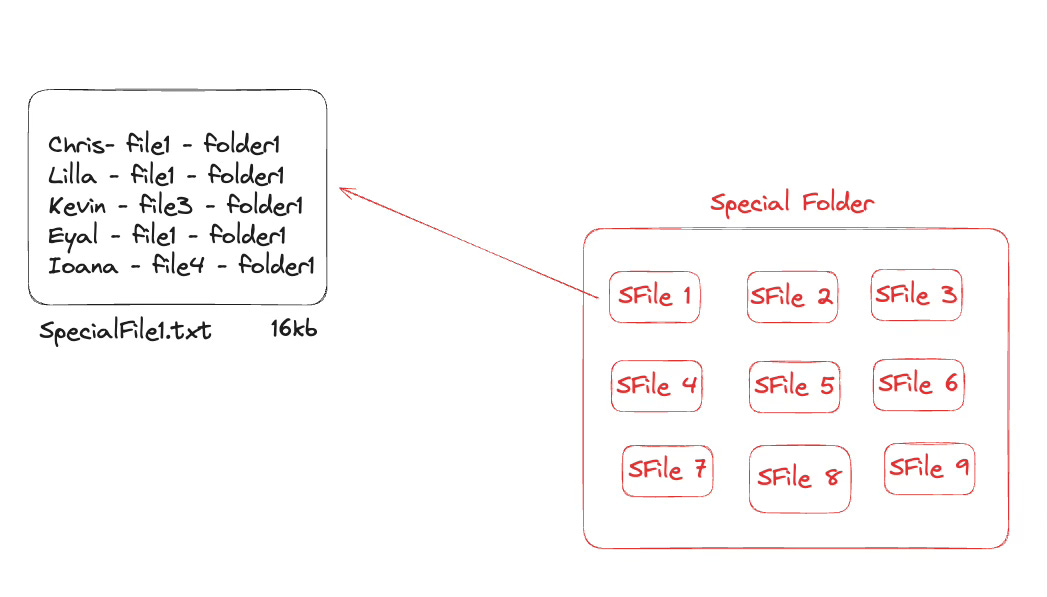
Now this is how a database generally stores data in the disk.
Returning Data with Index:
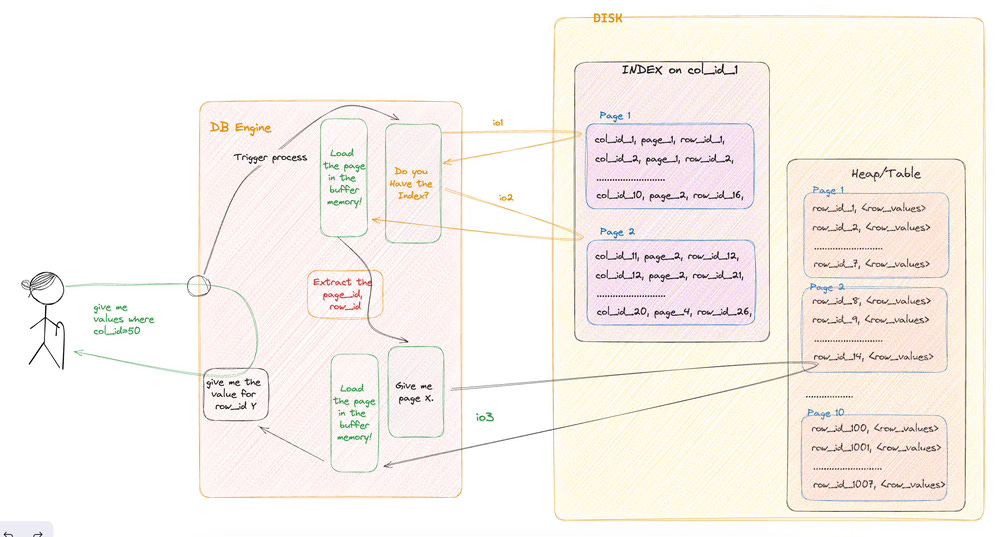
Based on image 006, if you wanna see how we get values for similar scenarios if we add an index on the column,
We asked DB engine, "give me all values for a row where column = 50"
DB engine will start a process
the process will see if this column has an index table or storage
it will find a storage
then will open page by page to look for the right column
Once it finds the right page it will load the page into the buffer memory
then it will extract the page_id, row_id for the info
then DB will go to the table storage area and directly load the page into the buffer memory by loading using the known page_id
the db engine will load the page into its buffer memory.
Then it will extract the right row values using the row_id
After that, the row will be returned to the user.
Food for thought:
if a row in the table has a size of 50 Bytes, then how many files will be needed to hold 1 million rows?
if index storage weighs 15 Bytes, then how many indexes can be stored on one page?
So to find a value without an index, what will be to count with a table of 1 million rows?
To find the same value(the table, same data set) with the index, what will be io count?
What might be the page size if we use uuid as the primary key vs a big int as the primary key?